Dados São Artefatos
O que contexto realmente é, onde as definições existentes deixam a desejar, e o que muda quando agentes de IA começam a agir sobre dados em velocidade de máquina.

Imagine esse cenário: Uma paleontóloga encontra um crânio de hipopótamo numa região onde hipopótamos não vivem há milhares de anos. Ela escreve um artigo cuidadoso sobre algum tipo de predador de pântano. Dentes grandes, mandíbula longa, o tipo de coisa que apavoravam moradores locais.
Os ossos eram reais. A história não era.
A mesma coisa acontece com dados, todo dia.
Puxamos uma linha da tabela, lemos um número, tiramos uma conclusão. Os números são reais. A história que construímos em torno deles, muitas vezes, não é. Porque dados são um registro feito por alguém, em algum lugar, sob condições que faziam sentido na época. Tira essas condições e você volta aos ossos de hipopótamo, contando histórias sobre monstros.
Quatro cenários
Aqui estão quatro cenários. Qualquer pessoa que trabalha com dados e ML provavelmente já viu algo parecido com cada um deles.
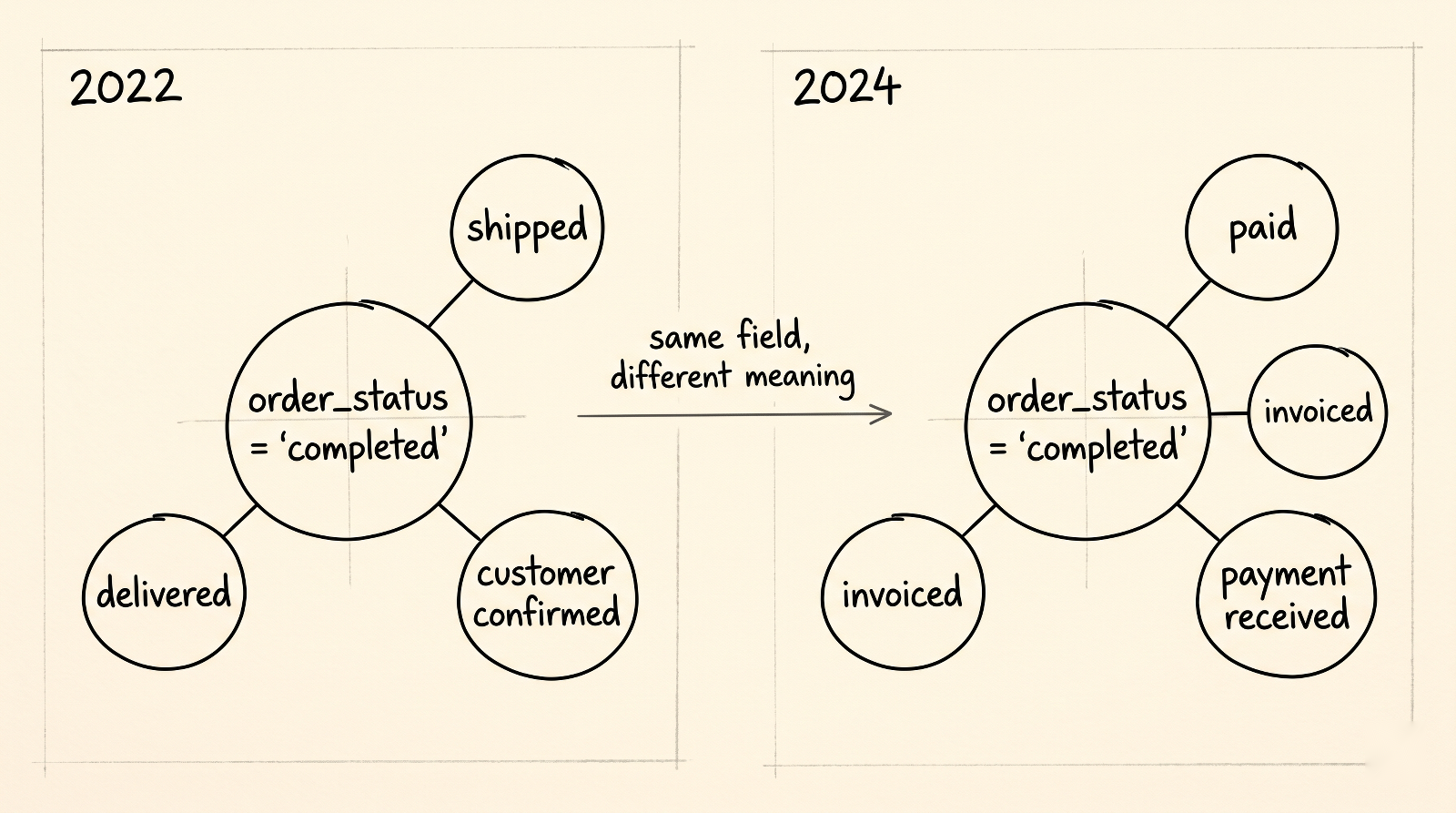
O campo de status que mudou de significado. Um time constrói um modelo de previsão usando order_status = 'completed'. Em 2022, "completed" significa que o pedido foi enviado. O modelo aprende como o "fulfillment" funciona. Em 2024, o time de Ops migra para um novo sistema de fulfillment e silenciosamente redefine "completed" para significar "pago". Mesmo campo, mesmo nome, evento totalmente diferente. O modelo continua gerando previsões. Elas pioram um pouco, depois pioram muito de uma vez. Quando alguém percebe, um trimestre inteiro de decisões foi tomado com base em previsões que respondiam a uma pergunta completamente diferente.
O rótulo de churn que ninguém é dono. Três times, uma palavra: churn (rotatividade de clientes). Vendas diz que o cliente deu "churn" quando a renovação não é assinada. Finanças diz que é quando o contrato termina. Produto entende que ocorre depois de trinta dias de inatividade. Os três números vão para o deck do conselho. Os três estão corretos, mas nenhum descreve a mesma coisa. O CEO está tomando decisões sobre estratégia de retenção em cima de três artefatos que parecem idênticos e não são.
O recomendador treinado em uma interface que não existe mais. Um time constrói um motor de recomendação com três anos de dados históricos de cliques. Resultados offline ótimos. Colocam em produção. Porém, seis meses antes, a interface (UI) tinha sido redesenhada. A página padrão de resultados de busca virou um carrossel horizontal. O carrossel mudou tudo: quais itens apareciam juntos, onde ficavam no campo visual do usuário, quão fácil era rolar e passar direto. O modelo foi treinado com cliques feitos em um produto que não existe mais. Os cliques eram reais. O problema é totalmente diferente agora.
O modelo de reservas de hotel treinado em outliers. Um marketplace de hotéis quer prever comportamento de reservas. Os dados de treinamento mais ricos estão entre 2020 e 2022. Anos de eventos densos e de alto sinal. Esses anos também descrevem um mundo com fronteiras fechadas, picos de demanda de trabalho remoto, sanitização como proposta de valor, e clientes que tratavam viagem como algo que talvez nunca mais teriam. O modelo se ajusta aos dados perfeitamente. Os dados se ajustam a um mundo que não existe mais.

O que estamos realmente olhando
O padrão por trás dos quatro cenários é o mesmo.
Cada linha de dados existe porque alguém, ou algum sistema, decidiu escrevê-la. As condições dessa escrita são parte do que o dado significa. Quem definiu o campo. Que processo disparou a linha. O que o time achava que o valor deveria representar na época. Essa é a parte do artefato. Tire essas condições e você volta aos ossos de hipopótamo e mitos.
Essas condições mudam: reorganizações, migrações, redesigns, pandemias, depreciações. O mesmo nome de campo em dois momentos diferentes são dois artefatos diferentes usando o mesmo nome. Essa é a parte da temporalidade.
Juntos, eles apontam para algo que a indústria ainda não nomeou direito.
Contexto de dados é a interseção de três coisas. O sinal que foi registrado. A fonte que o produziu. O momento em que foi registrado.
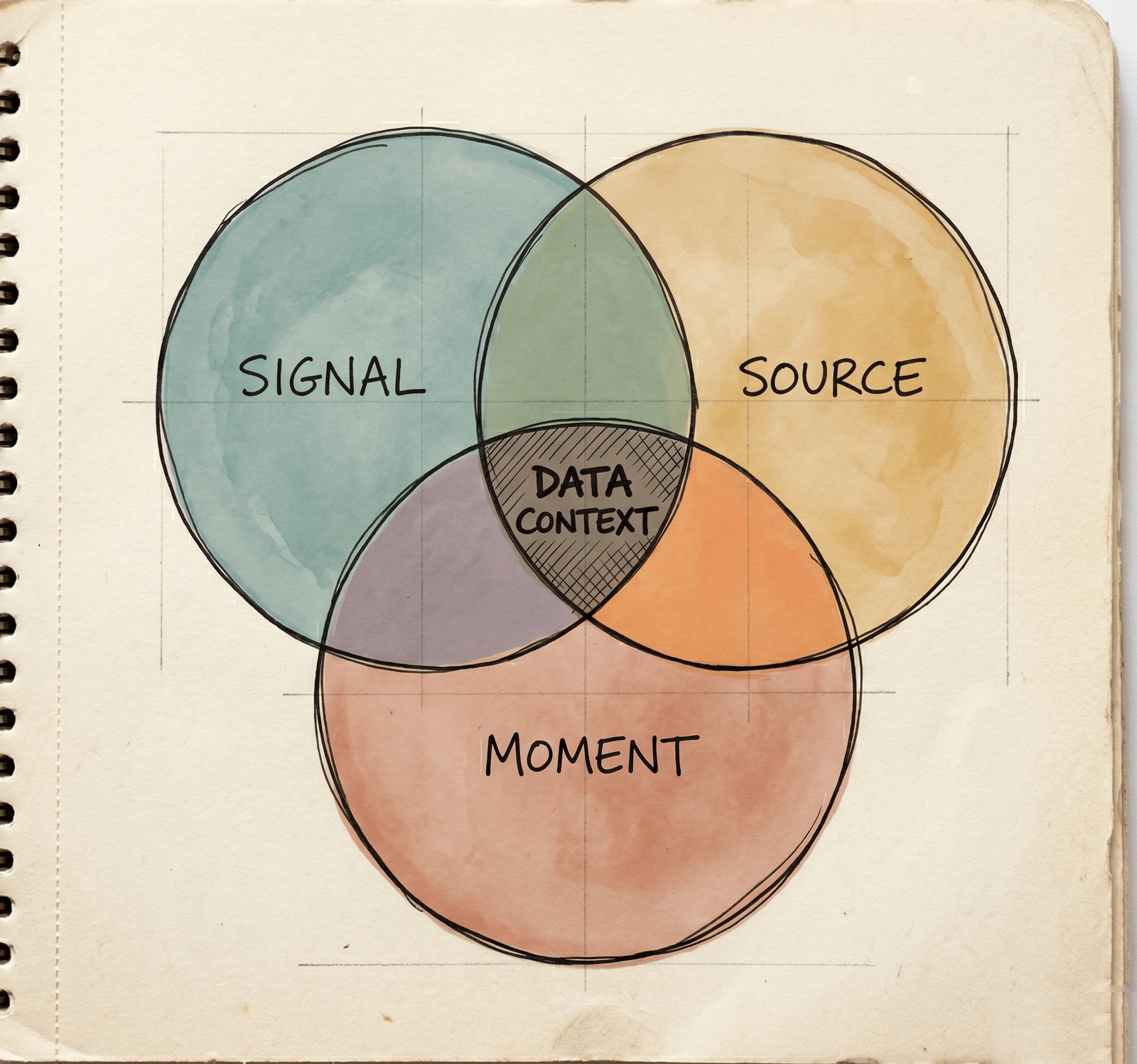
Quando os três estão presentes, você pode ler o sinal e confiar na leitura. Tire qualquer um e você está "chutando".
Por que as definições existentes não servem
As pessoas mais próximas do mundo dos dados vêm dizendo isso há anos. Profissionais descrevem seu próprio trabalho como tanto uma arte quanto uma ciência. Mais recentemente, começaram a nomear o Engenheiro de Contexto como um Arquiteto de Inteligência. A razão é a mesma que este post inteiro está explorando. Dados sozinhos nunca são suficientes. Bons profissionais de dados derivam significado através de criatividade, análise profunda, e o contexto que carregam na cabeça.
As ferramentas e produtos construídos em torno dos dados, porém, tratam isso como ciência pura. Essa lacuna é o que todo conceito existente de "contexto" está tentando, e falhando, em definir completamente.
Catálogos e metadados. Atlan, Collibra, Alation, DataHub, OpenMetadata, AWS Glue Data Catalog: Descrevem como um campo é chamado, quem é o dono, como é classificado, como se conecta com outros. Assumem que alguém já sabe o que ele significa e só precisa de um lugar para anotar. Estáticos e desatualizados por natureza.
Camadas semânticas. dbt Semantic Layer, Cube, LookML, AtScale: Mapeiam termos de negócio para SQL. Útil, mas descreve o estado atual do modelo, sem histórico e sem noção de drift.
RAG. Vector stores como Pinecone, Weaviate, Chroma. Orquestração como LangChain e LlamaIndex. Camadas comerciais como Glean e Vectara. Todos tratam contexto como algo que se busca no momento da query. O trabalho de contextual retrieval da própria Anthropic vai um passo além e mais próximo. Mas, ainda é algo que você busca no momento da pergunta, em vez de algo que o sistema mantém e deixa evoluir. A ausência de contexto nunca é mapeada como sinal (ou ausência dele).
Conhecimento tácito. O parente mais próximo. O The Tacit Dimension de Polanyi, o The Knowledge-Creating Company de Nonaka e Takeuchi, e em software, os runbooks e threads de Slack onde esses contextos realmente vivem. Mas conhecimento tácito é principalmente sobre conhecimento de processo. Como resolvemos incidentes ou como fazemos um release. Não cobre o que um artefato de dados específico significa agora ou há 1 ano. Ambos deveriam existir em conjunto.
Os posts recentes sobre context-graph (a16z, Ashu Garg, Foundation Capital) acertam bem o diagnóstico. Agentes precisam de mais do que estrutura e "schema". Empresas como Atlan e Interloom estão começando a construir em cima desse diagnóstico. O Roadmap de Data Engineering 2026 do Sanjeeb Panda vai mais longe e nomeia "contexto temporal" como uma dimensão de primeira classe. Útil, mas o temporal, nesse caso, significa quando o registro foi criado e quando foi atualizado. O temporal nos nossos cenários significa outra coisa: o mesmo registro descreve um mundo diferente hoje do que descrevia dois anos atrás, mesmo que nenhum campo, nenhum schema, nenhum timestamp tenha mudado. Mesma palavra. Problema diferente.
O grafo é provavelmente a metáfora certa, mas não o tipo estático que normalmente se constrói. Para reconstruir o que um dado significava quando foi escrito, cada vértice e aresta precisa ser versionado no tempo, ou um event log precisa replicar estados passados. A maioria dos grafos de contexto não é assim. São snapshots do estado atual, e não conseguem responder "o que esse campo significava seis meses atrás". Só o tipo versionado sobreviveria ao tempo.
Agente no loop
Um analista humano, diante de um número conflitante, pode pausar a tarefa. Pode ir até o time de dados ou de domínio e perguntar se o campo ainda significa o que costumava significar. Pode checar o log de migração, ou lembrar do redesign de 2022, ou simplesmente ter um pressentimento de que algo está errado. Essa pausa é onde o contexto vive.
Um agente de IA não pausa. É construído para sempre responder com confiança. Em cima de um artefato cujo significado expirou seis meses atrás, sem nenhum aviso para quem perguntou.
Previsões feitas com dados sem contexto respondem a uma pergunta diferente da que está sendo feita. O problema do crânio de hipopótamo, em velocidade de máquina, no caminho crítico de decisões que movem dinheiro ou impactam vidas.
O custo se acumula. Cada modelo, dashboard e agente subsequente herda o conceito errado. E conforme agentes começam a escrever de volta no sistema, estão produzindo novos artefatos, sob suas próprias condições, no seu próprio momento. A próxima geração de agentes vai ler esses artefatos da mesma forma: com confiança, sem contexto. Ou pior, com o contexto errado.
Agentes lendo artefatos escritos por outros agentes é um feedback loop com sinal atrasado e ruidoso, exatamente o que pessoas lidando com sistemas complexos temem (assunto para outro post).
Por muito tempo, os humanos eram a camada de contexto das empresas. Eles analisavam, perguntavam por aí, lembravam das mudanças de contexto. Agentes não fazem isso (veja mais sobre Ralph Wiggum Loop do Geoffrey Huntley). Tirar os humanos acelera as coisas, claro. Mas também remove aquilo que estava silenciosamente corrigindo esses problemas o tempo todo (ou pelo menos quase sempre). A próxima onda de IA dentro das empresas vai vir de sistemas que colocam essa camada de volta, explicitamente.
Esse é o insight que está direcionando a maior parte do meu trabalho na Dipolo AI. Se você já encarou o "problema do crânio de hipopótamo" mais vezes do que gostaria de admitir, eu adoraria conversar. Me manda uma mensagem: raphael@dipolo.ai.