Data Is an Artifact
What context actually is, where the existing definitions fall short, and what changes when AI agents start acting on data at machine speed.

Imagine this: A paleontologist finds a hippo skull in a region where hippos haven't lived for thousands of years. She writes a careful paper about some kind of swamp predator. Big teeth, long jaw, the kind of thing locals must have feared.
The bones were real. The story wasn't.
Same thing happens with data. Every day.
We pull a row, read a number, draw a conclusion. The numbers are real. The story we build around them, often, isn't. Because data is a record made by someone, somewhere, under conditions that made sense at the time. Strip those conditions away and you're back at hippo bones, telling stories about monsters.
Four scenes
Here are four scenes. Anyone working with data and ML probably has seen something like each of them.
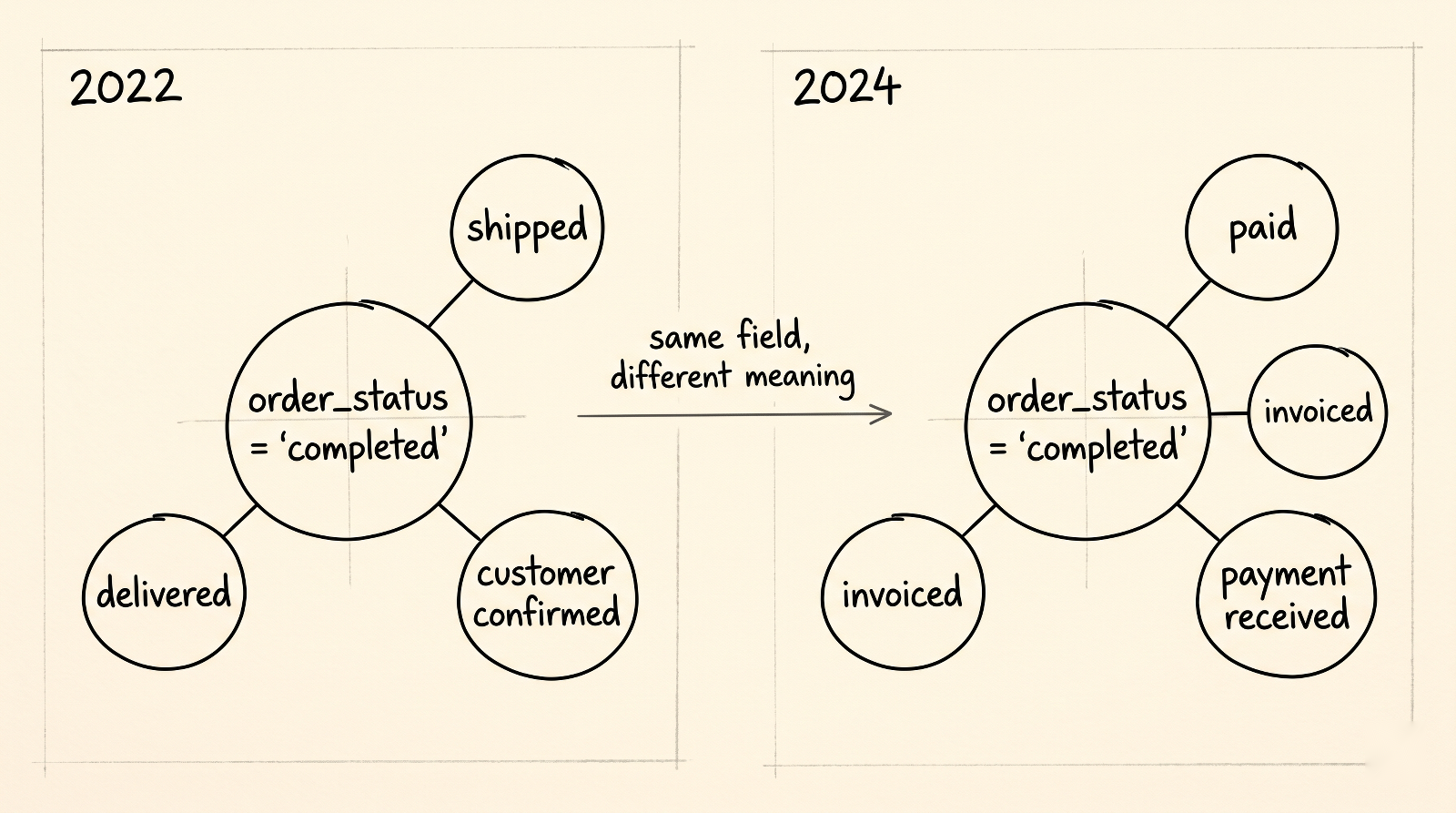
The status field that drifted. A team builds a forecasting model on order_status = 'completed'. In 2022, "completed" means the order shipped. The model learns how fulfillment works. In 2024, Ops migrates to a new fulfillment system and quietly redefines "completed" to mean "paid." Same field, same name, different event in the world. The model keeps producing forecasts. They get a little worse, then a lot worse. By the time someone notices, a quarter of decisions have been made on top of predictions that were answering an entirely different question.
The churn label nobody owns. Three teams, one word: churn. Sales says a customer churned when the renewal isn't signed. Finance says it when the contract ends. Product says it after thirty days of inactivity. All three numbers go into the board deck. All three are correct, but none of them describe the same thing. The CEO is making decisions about retention strategy on top of three artifacts that look identical and aren't.
The recommender trained on a UI that no longer exists. A team builds a recommendation engine on three years of historical click data. It tests well offline. They ship it. However, six months earlier, the interface had been redesigned. The default search results page became a horizontal carousel. The carousel changed everything: which items got shown together, where they sat in the user's eye, how easy it was to scroll past. The model was trained on clicks made on a product that no longer exists. The clicks were real. The problem space is totally different now.
The hotel booking model trained on outliers. A hotel marketplace wants to predict booking behavior. The richest training data sits in 2020 to 2022. Years of dense, high-signal events. Those years also describe a world with closed borders, work-from-anywhere demand spikes, sanitation as a value proposition, and customers who treated travel as something they might never get back. The model fits the data perfectly. The data fits a world that no longer exists.

What we're actually looking at
The pattern under all four is the same.
Every row of data exists because someone, or some system, decided to write it. The conditions of that writing are part of what the data means. Who defined the field. What process triggered the row. What the team thought the value was supposed to represent at the time. That's the artifact part. Strip those conditions away and you're back at hippo bones and myths.
Those conditions change: re-orgs, migrations, redesigns, pandemics, deprecations. The same field name at two different moments is two different artifacts wearing the same name. That's the temporality part.
Together, they point at something the industry hasn't quite named.
Data context is the intersection of three things. The signal that was recorded. The source that produced it. The moment it was recorded.
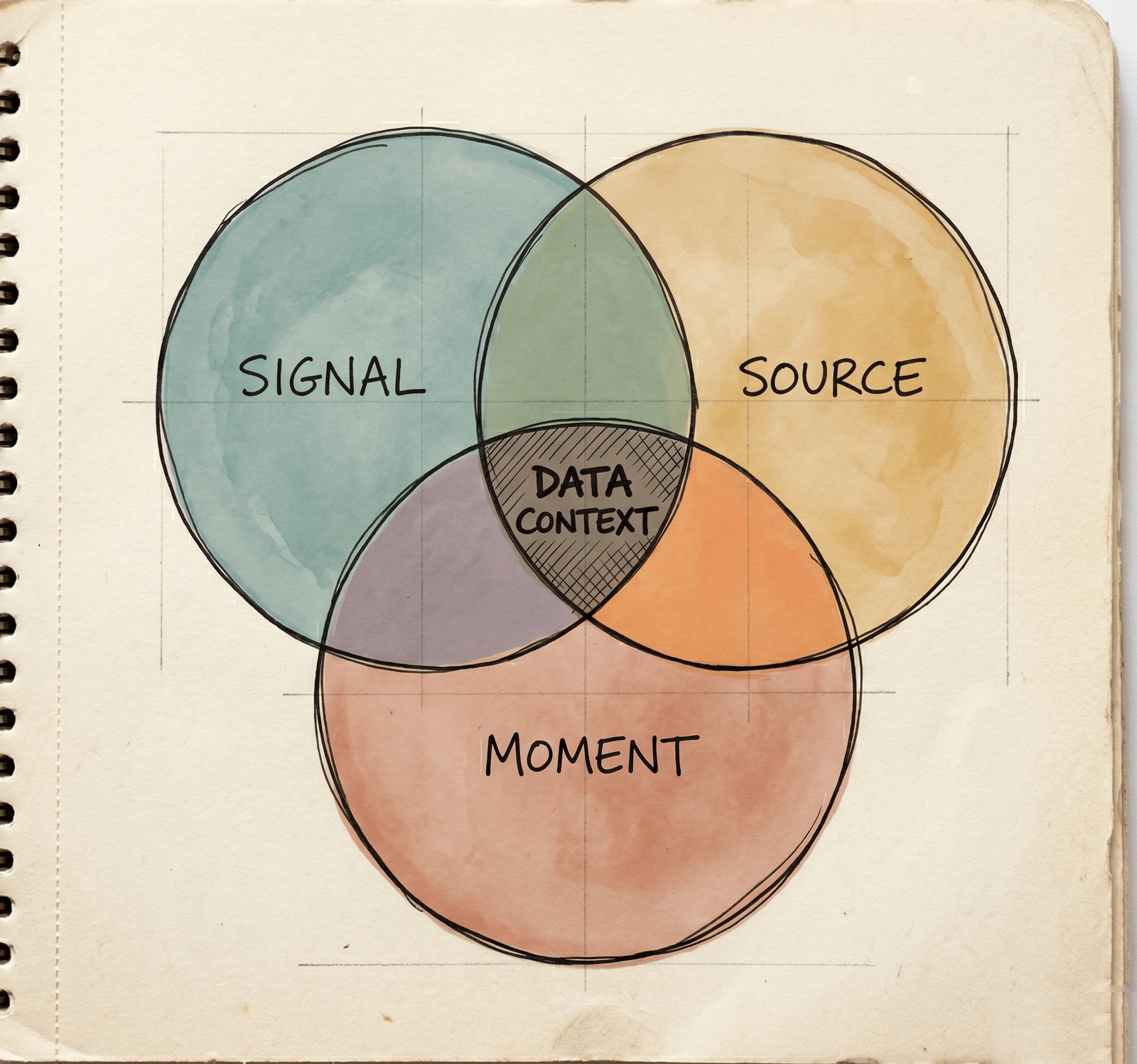
When all three are present, you can read the signal and trust the reading. Pull any one out and you're guessing.
Why the existing words don't fit
The people closest to data have been telling us this for a decade. Practitioners have long described their own work as as much an art as a science. More recently, they've started naming the Context Engineer as an Architect of Intelligence. The reason is the one this whole post is circling. Data alone is never enough. Good data professionals derive meaning through creativity, deep analysis, and the context they carry around in their heads.
The tools and products built around the data, though, mostly treat it as pure science. That gap is what every existing framing of "context" is trying, and failing, to close.
Catalogs and metadata. Atlan, Collibra, Alation, DataHub, OpenMetadata, AWS Glue Data Catalog. They describe what a field is called, who owns it, how it's classified, how it's connected to others. They assume someone already knows what it means and just needs a place to write it down. Static and outdated by design.
Semantic layers. dbt Semantic Layer, Cube, LookML, AtScale. They map business terms to SQL. That's useful, but it describes the current state of the model, with no history and no sense of drift.
RAG. Vector stores like Pinecone, Weaviate, Chroma. Orchestration like LangChain and LlamaIndex. Commercial layers like Glean and Vectara. They treat context as something you retrieve at query time. Anthropic's own contextual retrieval work is a step closer. Still query-time. Still something you fetch at the moment of the question, rather than something the system maintains and lets evolve.
Tacit knowledge. The closest cousin. Polanyi's The Tacit Dimension, Nonaka and Takeuchi's The Knowledge-Creating Company, and in software, the runbooks and Slack threads where this stuff actually lives. But tacit knowledge is mostly about process knowledge. How we resolve incidents. How we run a release. It doesn't cover what a specific data artifact means right now.
The recent context-graph posts (a16z, Ashu Garg, Foundation Capital) get the diagnosis right. Agents need more than a schema. Companies like Atlan and Interloom are starting to ship on that diagnosis. Sanjeeb Panda's 2026 Data Engineering Roadmap goes further and names "temporal context" as a first-class dimension. Useful, but his temporal means when the record was created and when it was updated. The temporal in our scenes means something else: the same record describes a different world today than it did two years ago, even if no field, no schema, no timestamp has moved. Same word. Different problem.
The graph is probably the right metaphor, but not the static kind usually built. To reconstruct what a data point meant when it was written, every vertex and edge has to be versioned in time, or an event log has to replay past states. Most context graphs aren't that. They're current-state snapshots, and they can't answer "what did this field mean six months ago." Only the versioned kind survives drift.
Agent is in the loop
A human analyst, faced with a confusing number, might pause. They might walk over to the data or domain teams and ask whether the field still means what it used to. They might check the migration log, or remember the 2022 redesign, or just have a gut feeling that something is off. That pause is where context lives.
An AI agent doesn't pause. It's built to always answer confidently. On top of an artifact whose meaning expired six months ago, with no warning to the person who asked.
Predictions made on data without context answer a different question than the one being asked. The hippo skull problem, at machine speed, on the critical path of decisions that move money.
The cost compounds. Every downstream model, dashboard, and agent inherits the misframing. And as agents start writing back into the system, they're producing new artifacts, under their own conditions, at their own moment. The next generation of agents will read those artifacts the same way: confidently, without context. Or worse, with the wrong context.
Agents reading artifacts written by other agents is a feedback loop with delayed, noisy signal, the kind complex-systems people warn you about (topic for another post).
For a long time, the humans in the loop were the context layer. They paused, asked around, remembered the redesign. Agents don't do that (see Ralph Wiggum Loop from Geoffrey Huntley). Taking the humans out speeds things up, sure. It also removes the thing that was quietly catching these problems all along. The next wave of useful AI inside companies will come from systems that put that layer back, explicitly.
This is the insight that's driving most of my work at Dipolo AI. If you're someone who's run into the "hippo skull problem" more times than you'd like to admit, I'd love to talk. Send me a message: raphael@dipolo.ai.